Track
Podstawy danych w Pythonie
28 godz.
Lista wiązana to struktura danych, która odgrywa kluczową rolę w organizacji i zarządzaniu danymi. Zawiera sekwencję węzłów przechowywanych w losowych miejscach w pamięci, co pozwala na efektywne zarządzanie pamięcią. Każdy węzeł listy wiązanej zawiera dwa główne elementy: część z danymi oraz odwołanie do następnego węzła w sekwencji.
Jeśli ten koncept brzmi na pierwszy rzut oka skomplikowanie, nie martw się!
Rozłożymy go na czynniki pierwsze, aby wyjaśnić, czym są listy wiązane, dlaczego ich używamy i jakie dają unikalne korzyści.
Listy wiązane powstały, aby przezwyciężyć różne wady związane z przechowywaniem danych w zwykłych listach i tablicach, jak opisano poniżej:
W listach wstawienie lub usunięcie elementu na dowolnej pozycji innej niż koniec wymaga przesunięcia wszystkich kolejnych elementów. Proces ten ma złożoność czasową O(n) i może znacząco pogorszyć wydajność, zwłaszcza gdy rozmiar listy rośnie. Jeśli nie znasz jeszcze sposobu działania list ani ich implementacji, możesz przeczytać nasz tutorial o listach w Pythonie.
Listy wiązane działają jednak inaczej. Przechowują elementy w różnych, nieciągłych obszarach pamięci i łączą je wskaźnikami do kolejnych węzłów. Taka struktura pozwala dodawać lub usuwać elementy w dowolnym miejscu poprzez proste modyfikowanie połączeń tak, by włączyć nowy element lub ominąć usunięty.
Gdy masz bezpośrednie odwołanie do węzła w miejscu wstawiania lub usuwania, sama operacja ma złożoność O(1). Nadal jednak znalezienie tej pozycji wymaga przeglądu O(n), więc korzyść O(1) dotyczy sytuacji, gdy już posiadasz wskaźnik do odpowiedniego węzła (np. gdy pracujesz na początku listy).
Listy w Pythonie są dynamicznymi tablicami, co oznacza, że dają elastyczność zmiany rozmiaru.
Proces ten obejmuje jednak szereg złożonych operacji, w tym realokację tablicy do nowego, większego bloku pamięci. Taka realokacja jest nieefektywna, ponieważ elementy są kopiowane do nowego bloku, potencjalnie przydzielając więcej miejsca, niż jest to od razu potrzebne.
Z kolei listy wiązane mogą rosnąć i kurczyć się dynamicznie bez potrzeby realokacji czy zmiany rozmiaru. Czyni je to preferowanym wyborem w zadaniach wymagających dużej elastyczności.
Listy przydzielają pamięć dla wszystkich swoich elementów w jednym ciągłym bloku. Jeśli lista musi urosnąć poza swój początkowy rozmiar, musi przydzielić nowy, większy blok ciągłej pamięci, a następnie skopiować do niego wszystkie istniejące elementy. Proces ten jest czasochłonny i nieefektywny, zwłaszcza dla dużych list. Z drugiej strony, jeśli początkowy rozmiar listy zostanie przeszacowany, niewykorzystana pamięć się marnuje.
W przeciwieństwie do tego, listy wiązane przydzielają pamięć osobno dla każdego elementu. Taka struktura prowadzi do lepszego wykorzystania pamięci, ponieważ pamięć dla nowych elementów może być przydzielana w momencie ich dodawania.
Chociaż listy wiązane oferują pewne korzyści względem zwykłych list i tablic, takie jak dynamiczny rozmiar i efektywność pamięciowa, mają też ograniczenia. Ponieważ dla każdego elementu trzeba przechowywać wskaźnik do następnego węzła, użycie pamięci na element jest większe niż w listach wiązanych. Ponadto ta struktura danych nie pozwala na bezpośredni dostęp do danych. Dostęp do elementu wymaga sekwencyjnego przejścia od początku listy, co skutkuje złożonością wyszukiwania O(n).
Wybór między listą wiązaną a tablicą zależy od konkretnych potrzeb aplikacji. Listy wiązane są najbardziej przydatne, gdy:
Istnieją trzy rodzaje list wiązanych, z których każdy oferuje unikalne zalety w różnych scenariuszach. Są to:
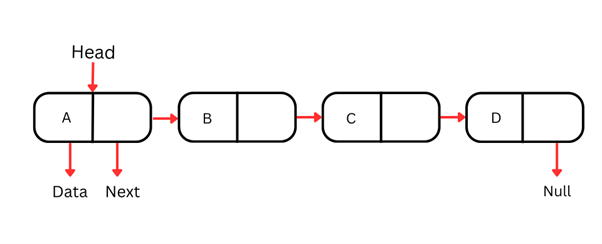
Lista jednokierunkowa
Lista jednokierunkowa to najprostszy typ listy wiązanej, w której każdy węzeł zawiera dane oraz odwołanie do następnego węzła w sekwencji. Można ją przeglądać tylko w jednym kierunku — od głowy (pierwszego węzła) do ogona (ostatniego węzła).
Każdy węzeł listy jednokierunkowej zwykle składa się z dwóch części:
Ponieważ te struktury danych można przeglądać tylko w jednym kierunku, dostęp do konkretnego elementu po wartości lub indeksie wymaga rozpoczęcia od głowy i sekwencyjnego przechodzenia przez węzły, aż znajdziesz żądany. Operacja ta ma złożoność O(n), co czyni ją mniej wydajną dla dużych list.
Wstawianie i usuwanie węzła na początku listy jednokierunkowej jest bardzo wydajne i ma złożoność O(1). Jednak wstawianie i usuwanie w środku lub na końcu wymaga przejścia listy do tego miejsca, co prowadzi do złożoności O(n).
Konstrukcja list jednokierunkowych sprawia, że są użyteczną strukturą danych przy operacjach wykonywanych na początku listy.
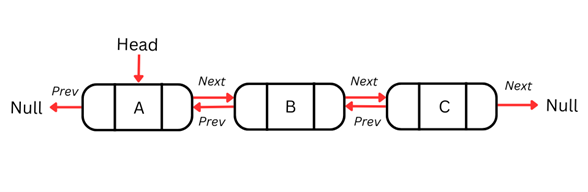
Lista dwukierunkowa
Jedną z wad list jednokierunkowych jest to, że można je przeglądać tylko w jednym kierunku i nie można wrócić do poprzedniego węzła w razie potrzeby. To ograniczenie utrudnia operacje wymagające dwukierunkowej nawigacji.
Listy dwukierunkowe rozwiązują ten problem, dodając w każdym węźle dodatkowy wskaźnik, dzięki czemu listę można przeglądać w obu kierunkach. Każdy węzeł listy dwukierunkowej zawiera trzy elementy: dane, wskaźnik do następnego węzła oraz wskaźnik do poprzedniego węzła.
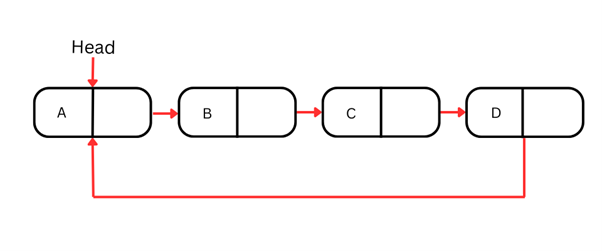
Lista cykliczna
Listy cykliczne to wyspecjalizowana forma listy wiązanej, w której ostatni węzeł wskazuje z powrotem na pierwszy węzeł, tworząc strukturę kołową. Oznacza to, że w przeciwieństwie do list jednokierunkowych i dwukierunkowych, które poznaliśmy do tej pory, lista cykliczna nie kończy się — zamiast tego zapętla się.
Cykliczny charakter list cyklicznych sprawia, że są idealne w scenariuszach wymagających ciągłego przechodzenia przez elementy, takich jak gry planszowe, w których po ostatnim graczu kolejka wraca do pierwszego, lub w algorytmach obliczeniowych, takich jak szeregowanie okrężne (round-robin).
Warto rzucić okiem, jak listy wiązane wypadają na tle list w Pythonie:
| Operacja | Lista jednokierunkowa | Tablica/Lista Pythona |
|---|---|---|
| Dostęp po indeksie | O(n) | O(1) |
| Wyszukiwanie po wartości | O(n) | O(n) |
| Wstawienie na początku | O(1) | O(n) |
| Wstawienie na końcu | O(n) | O(1) amortyzowane |
| Wstawienie w środku | O(n) | O(n) |
| Usunięcie na początku | O(1) | O(n) |
| Usunięcie na końcu | O(n) | O(1) amortyzowane |
Najważniejszy wniosek: listy wiązane wygrywają przy wstawieniach i usunięciach na początku (O(1)), ale przegrywają we wszystkim innym. Jeśli nie dodajesz ani nie usuwasz często elementów na początku swojej struktury danych, zwykła lista Pythona będzie prawdopodobnie lepszym wyborem.
Skoro rozumiemy już, czym są listy wiązane, po co ich używamy i jakie mają warianty, przejdźmy do implementacji tych struktur danych w Pythonie. Notatnik do tego tutorialu jest dostępny także w tym zeszycie DataLab; jeśli utworzysz kopię, możesz edytować i uruchamiać kod. To świetna opcja, jeśli napotkasz problemy z uruchomieniem kodu u siebie!
Jak dowiedzieliśmy się wcześniej, węzeł to element listy wiązanej, który przechowuje dane i odwołanie do następnego węzła w sekwencji. Oto jak możesz zdefiniować węzeł w Pythonie:
class Node:
def __init__(self, data):
self.data = data
self.next = None
def __repr__(self):
return f"Node({self.data})"Powyższy kod inicjalizuje węzeł, wykonując dwie główne akcje: atrybut „data” węzła otrzymuje wartość reprezentującą właściwą informację, którą węzeł ma zawierać. Atrybut „next” reprezentuje adres następnego węzła. Jest on obecnie ustawiony na None, co oznacza, że nie łączy się z żadnym innym węzłem na liście. W miarę dodawania nowych węzłów do listy wiązanej, atrybut ten będzie aktualizowany tak, by wskazywać kolejny węzeł.
Następnie musimy utworzyć klasę listy wiązanej. Będzie ona kapsułkować wszystkie operacje zarządzania węzłami, takie jak wstawianie i usuwanie. Zaczniemy od zainicjalizowania listy wiązanej:
class LinkedList:
def __init__(self):
self.head = None # Initialize head as NoneUstawiając self.head na None, stwierdzamy, że lista wiązana jest początkowo pusta i nie ma w niej węzłów, do których można by się odwołać. Teraz przejdziemy do wypełniania listy poprzez wstawianie nowych węzłów.
W klasie LinkedList dodamy metodę tworzącą nowy węzeł i umieszczającą go na początku listy:
def insertAtBeginning(self, new_data):
new_node = Node(new_data) # Create a new node
new_node.next = self.head # Next for new node becomes the current head
self.head = new_node # Head now points to the new nodeZa każdym razem, gdy wywołasz powyższą metodę, zostanie utworzony nowy węzeł z podanymi przez ciebie danymi. Wskaźnik next tego nowego węzła jest ustawiany na bieżącą głowę listy, co umieszcza ten węzeł przed istniejącymi elementami. Na końcu nowo utworzony węzeł staje się głową listy.
Teraz wypełnimy listę wiązaną serią słów, aby lepiej zrozumieć, jak działa operacja wstawiania. Aby to osiągnąć, najpierw utwórzmy metodę przeznaczoną do przechodzenia po liście i wypisywania jej zawartości:
def printList(self):
temp = self.head # Start from the head of the list
while temp:
print(temp.data,end=' ') # Print the data in the current node
temp = temp.next # Move to the next node
print() # Ensures the output is followed by a new linePowyższa metoda wydrukuje zawartość naszej listy wiązanej. Przejdźmy teraz do użycia zdefiniowanych metod, aby wypełnić listę serią słów: „the quick brown fox”.
if __name__ == '__main__':
# Create a new LinkedList instance
llist = LinkedList()
# Insert each letter at the beginning using the method we created
llist.insertAtBeginning('fox')
llist.insertAtBeginning('brown')
llist.insertAtBeginning('quick')
llist.insertAtBeginning('the')
# Now 'the' is the head of the list, followed by 'quick', then 'brown' and 'fox'
# Print the list
llist.printList()Powyższe linie kodu powinny dać następujący wynik:
"the quick brown fox"
Utworzymy teraz metodę o nazwie insertAtEnd w klasie LinkedList, aby utworzyć nowy węzeł na końcu listy. Jeśli lista jest pusta, nowy węzeł stanie się głową listy. W przeciwnym razie zostanie dołączony do aktualnego ostatniego węzła na liście. Zobaczmy, jak działa to w praktyce:
def insertAtEnd(self, new_data):
new_node = Node(new_data)
if self.head is None:
self.head = new_node
return
last = self.head
while last.next:
last = last.next
last.next = new_nodePowyższa metoda zaczyna od utworzenia nowego węzła. Następnie sprawdza, czy lista jest pusta, i jeśli tak, nowy węzeł zostaje przypisany jako głowa tej listy. W przeciwnym razie przechodzi listę, aby znaleźć ostatni węzeł, i ustawia wskaźnik tego węzła na nowy węzeł.
Musimy teraz dodać tę metodę do naszej klasy LinkedList i użyć jej do dodania słowa na końcu listy. Aby to zrobić, zmodyfikuj swoją funkcję główną, aby wyglądała tak:
if __name__ == '__main__':
llist = LinkedList()
# Insert words at the beginning
llist.insertAtBeginning('fox')
llist.insertAtBeginning('brown')
llist.insertAtBeginning('quick')
llist.insertAtBeginning('the')
# Insert a word at the end
llist.insertAtEnd('jumps')
# Print the list
llist.printList()Zauważ, że po prostu wywołaliśmy metodę insertAtEnd, aby wypisać słowo „jumps” na końcu listy. Powyższy kod powinien dać następujący wynik:
"the quick brown fox jumps"
Usunięcie pierwszego węzła listy wiązanej jest proste, ponieważ polega jedynie na ustawieniu głowy listy na drugi węzeł. W ten sposób pierwszy węzeł nie będzie już częścią listy. Aby to zrobić, dodaj do klasy LinkedList następującą metodę:
def deleteFromBeginning(self):
if self.head is None:
return "The list is empty" # If the list is empty, return this string
self.head = self.head.next # Otherwise, remove the head by making the next node the new headAby usunąć ostatni węzeł listy wiązanej, musimy przejść listę, znaleźć przedostatni węzeł i zmienić jego wskaźnik next na None. W ten sposób ostatni węzeł nie będzie już częścią listy. Skopiuj i wklej poniższą metodę do swojej klasy LinkedList, aby to osiągnąć:
def deleteFromEnd(self):
if self.head is None:
return "The list is empty"
if self.head.next is None:
self.head = None # If there's only one node, remove the head by making it None
return
temp = self.head
while temp.next.next: # Otherwise, go to the second-last node
temp = temp.next
temp.next = None # Remove the last node by setting the next pointer of the second-last node to NonePowyższa metoda najpierw sprawdza, czy lista wiązana jest pusta, zwracając komunikat do użytkownika, jeśli tak. W przeciwnym razie, jeśli lista zawiera pojedynczy węzeł, ten węzeł jest usuwany. Dla list z wieloma węzłami metoda lokalizuje przedostatni węzeł i aktualizuje jego odwołanie do następnego węzła na None.
Zaktualizujmy teraz funkcję główną, aby usuwać elementy z początku i końca listy wiązanej:
if __name__ == '__main__':
llist = LinkedList()
# Insert words at the beginning
llist.insertAtBeginning('fox')
llist.insertAtBeginning('brown')
llist.insertAtBeginning('quick')
llist.insertAtBeginning('the')
# Insert a word at the end
llist.insertAtEnd('jumps')
# Print the list before deletion
print("List before deletion:")
llist.printList()
# Deleting nodes from the beginning and end
llist.deleteFromBeginning()
llist.deleteFromEnd()
# Print the list after deletion
print("List after deletion:")
llist.printList()Powyższy kod wydrukuje listę przed i po usuwaniu, pokazując, jak działają operacje wstawiania i usuwania w listach wiązanych. Po uruchomieniu tego kodu powinieneś zobaczyć następujący wynik:
List before deletion:
the quick brown fox jumps
List after deletion:
quick brown foxOstatnią operacją, której nauczymy się w tym rozdziale, jest wyszukiwanie konkretnej wartości na liście wiązanej. Aby to zrobić, metoda powinna zacząć od głowy listy i iterować przez każdy węzeł, sprawdzając, czy dane węzła odpowiadają szukanej wartości. Oto praktyczna implementacja tej operacji:
def search(self, value):
current = self.head # Start with the head of the list
position = 0 # Counter to keep track of the position
while current: # Traverse the list
if current.data == value: # Compare the list's data to the search value
return f"Value '{value}' found at position {position}" # Print the value if a match is found
current = current.next
position += 1
return f"Value '{value}' not found in the list" Aby znaleźć konkretne wartości na utworzonej przez nas liście wiązanej, zaktualizuj swoją funkcję główną, aby uwzględniała właśnie dodaną metodę wyszukiwania:
if __name__ == '__main__':
llist = LinkedList()
# Insert words at the beginning
llist.insertAtBeginning('fox')
llist.insertAtBeginning('brown')
llist.insertAtBeginning('quick')
llist.insertAtBeginning('the')
# Insert a word at the end
llist.insertAtEnd('jumps')
# Print the list before deletion
print("List before deletion:")
llist.printList()
# Deleting nodes from beginning and end
llist.deleteFromBeginning()
llist.deleteFromEnd()
# Print the list after deletion
print("List after deletion:")
llist.printList()
# Search for 'quick' and 'lazy' in the list
print(llist.search('quick')) # Expected to find
print(llist.search('lazy')) # Expected not to findPowyższy kod da następujący wynik:
List before deletion:
the quick brown fox jumps
List after deletion:
quick brown fox
Value 'quick' found at position 0
Value 'lazy' not found in the listSłowo „quick” zostało pomyślnie zlokalizowane na liście wiązanej, ponieważ znajduje się na pierwszej pozycji listy. Natomiast słowa „lazy” nie ma na liście, dlatego nie zostało znalezione.
Jeśli dotarłeś aż tutaj — gratulacje! Masz już solidne zrozumienie podstawowych zasad list wiązanych, w tym ich budowy, rodzajów, sposobów dodawania i usuwania elementów oraz ich przeglądania.
Ale na tym podróż się nie kończy. Listy wiązane to dopiero początek świata struktur danych i algorytmów. Oto kilka potencjalnych kolejnych kroków, które pomogą ci pogłębić wiedzę w tym temacie:
Wejdź w praktyczne zastosowania list wiązanych, integrując je z projektem programistycznym lub data science. Listy wiązane są używane do tworzenia systemów plików, konstruowania tablic haszujących, a nawet do budowy systemów nawigacji GPS i gier planszowych. Aby zacząć z własnymi projektami, sprawdź nasze darmowe, prowadzone projekty data science, które nauczą cię rozwiązywać problemy ze świata rzeczywistego w Pythonie, R i SQL.
Nauka innych struktur danych, takich jak drzewa, stosy i kolejki, to naturalny krok po zrozumieniu list wiązanych. Te struktury bazują na zasadach list wiązanych, pomagając efektywnie rozwiązywać szerszy zakres problemów obliczeniowych. Drzewa i drzewa BST, na przykład, rozszerzają koncepcję list wiązanych do formy hierarchicznej, umożliwiając każdemu węzłowi łączenie się z wieloma elementami w strukturze danych.
Jeśli te pojęcia brzmią dla ciebie obco, nie martw się! Datacamp ma cały kurs poświęcony strukturom danych i algorytmom w Pythonie, który omówi je znacznie dokładniej. Najpierw poznasz struktury danych, takie jak stosy, drzewa, tablice haszujące, kolejki i grafy. W miarę postępów zrozumiesz algorytmy wyszukiwania i sortowania, co pomoże ci stać się bardziej efektywnym programistą i rozwiązywać problemy sprawniej.
W tym tutorialu zaimplementowaliśmy listy jednokierunkowe, obejmując operacje takie jak wstawianie, usuwanie i przeglądanie.
Możesz pójść o krok dalej, ucząc się implementacji list dwukierunkowych i cyklicznych. Skip lists to kolejne rozwinięcie list wiązanych, które umożliwiają szybsze operacje wyszukiwania dzięki przyspieszonemu dostępowi do elementów.
Poznanie tych zaawansowanych struktur danych wyniesie twoje umiejętności techniczne na wyższy poziom i znacząco poprawi twoje możliwości programistyczne, przygotowując cię na bardziej złożone wyzwania w takich dziedzinach jak data science, rozwój oprogramowania czy inżynieria uczenia maszynowego.
Jeśli przed podjęciem tych zaawansowanych tematów wolisz bardziej przyjazne dla początkujących wprowadzenie do programowania, zajrzyj na naszą ścieżkę kariery Python Programmer. Oferuje serię kursów, które nauczą cię podstaw języka.
Ucz się Pythona dalej!
Track
Track
course