
programa
Fundamentos de Datos en Python
28 h
Una lista enlazada es una estructura de datos que desempeña un papel clave en la organización y gestión de la información. Contiene una serie de nodos almacenados en ubicaciones aleatorias de memoria, lo que permite gestionar la memoria de forma eficiente. Cada nodo de una lista enlazada incluye dos componentes principales: la parte de datos y una referencia al siguiente nodo de la secuencia.
Si a primera vista el concepto te parece complejo, ¡no te preocupes!
Vamos a desgranarlo hasta los fundamentos para explicar qué son las listas enlazadas, por qué las usamos y las ventajas que ofrecen.
Las listas enlazadas nacieron para superar varios inconvenientes de almacenar datos en listas y arrays convencionales, como verás a continuación:
En las listas, insertar o eliminar un elemento en cualquier posición que no sea el final obliga a desplazar todos los elementos posteriores. Este proceso tiene complejidad temporal O(n) y puede penalizar mucho el rendimiento, especialmente a medida que crece el tamaño de la lista. Si aún no estás familiarizado con cómo funcionan las listas o su implementación, puedes leer nuestro tutorial sobre listas en Python.
Las listas enlazadas, en cambio, funcionan de forma distinta. Almacenan los elementos en ubicaciones de memoria no contiguas y los conectan mediante punteros a los nodos siguientes. Esta estructura permite añadir o eliminar elementos en cualquier posición simplemente modificando los enlaces para incluir el nuevo elemento o saltarse el eliminado.
Una vez tienes una referencia directa al nodo en el punto de inserción o borrado, la operación en sí es O(1). Aun así, localizar esa posición requiere un recorrido O(n), por lo que el beneficio O(1) solo aplica cuando ya tienes un puntero al nodo relevante (por ejemplo, cuando trabajas en la cabeza de la lista).
Las listas de Python son arrays dinámicos, lo que significa que permiten modificar su tamaño.
Sin embargo, este proceso implica operaciones complejas, como reasignar el array a un bloque de memoria más grande. Esta reasignación es ineficiente porque los elementos se copian a un bloque nuevo, pudiendo reservar más espacio del necesario en ese momento.
Por el contrario, las listas enlazadas pueden crecer y encogerse dinámicamente sin necesidad de reasignación ni redimensionado. Por eso resultan preferibles en tareas que requieren gran flexibilidad.
Las listas reservan memoria para todos sus elementos en un bloque contiguo. Si una lista necesita crecer más allá de su tamaño inicial, debe reservar un bloque contiguo más grande y copiar allí todos los elementos existentes. Este proceso consume tiempo y es ineficiente, especialmente en listas grandes. Por otro lado, si se sobreestima el tamaño inicial, la memoria no utilizada se desperdicia.
En cambio, las listas enlazadas reservan memoria por elemento. Esta estructura mejora el uso de la memoria, ya que la memoria para nuevos elementos puede asignarse a medida que se añaden.
Aunque las listas enlazadas ofrecen ventajas sobre las listas y arrays convencionales, como tamaño dinámico y eficiencia de memoria, también tienen limitaciones. Como es necesario almacenar punteros para referenciar el siguiente nodo, el uso de memoria por elemento es mayor. Además, esta estructura no permite acceso directo a los datos. Acceder a un elemento exige recorrer secuencialmente desde el principio, con una complejidad O(n) en tiempo de búsqueda.
La elección entre usar una lista enlazada o un array depende de las necesidades de tu aplicación. Las listas enlazadas son más útiles cuando:
Existen tres tipos de listas enlazadas, cada una con ventajas particulares según el caso de uso. Son:
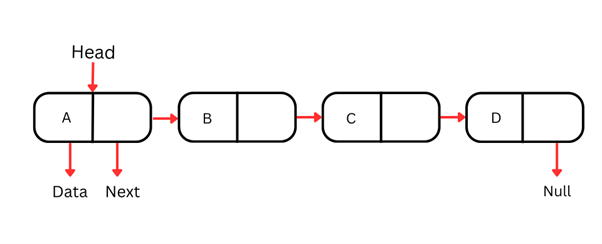
Lista simplemente enlazada
Una lista simplemente enlazada es el tipo más sencillo: cada nodo contiene datos y una referencia al siguiente nodo de la secuencia. Solo se puede recorrer en una dirección: desde la cabeza (primer nodo) hasta la cola (último nodo).
Cada nodo de una lista simplemente enlazada suele tener dos partes:
Como estas estructuras solo se recorren en una dirección, acceder a un elemento concreto por valor o índice requiere empezar en la cabeza e ir avanzando nodo a nodo hasta encontrarlo. Esta operación es O(n), por lo que resulta menos eficiente en listas grandes.
Insertar y eliminar un nodo al principio de una lista simplemente enlazada es muy eficiente, con complejidad O(1). Sin embargo, las inserciones y borrados en medio o al final exigen recorrer la lista hasta ese punto, lo que implica O(n).
Su diseño las hace especialmente útiles cuando realizas operaciones en el inicio de la lista.
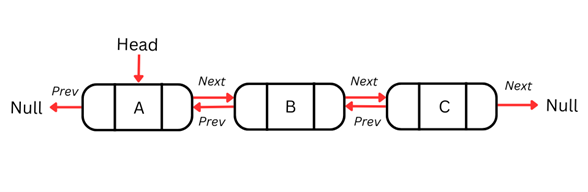
Lista doblemente enlazada
Una desventaja de las listas simplemente enlazadas es que solo se pueden recorrer en una dirección y no es posible volver al nodo anterior si hace falta. Esta restricción limita las operaciones que requieren navegación bidireccional.
Las listas doblemente enlazadas resuelven este problema incorporando un puntero adicional en cada nodo, de modo que la lista pueda recorrerse en ambos sentidos. Cada nodo contiene tres elementos: los datos, un puntero al siguiente nodo y un puntero al nodo anterior.
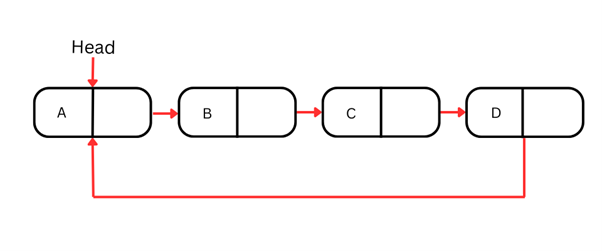
Lista circular
Las listas circulares son una variante en la que el último nodo apunta de nuevo al primero, creando una estructura cíclica. A diferencia de las listas simplemente o doblemente enlazadas que hemos visto, aquí la lista no termina: se cierra en bucle.
Esa naturaleza cíclica las hace ideales para escenarios que se repiten continuamente, como juegos de mesa en los que tras el último jugador vuelve el primero, o algoritmos como la planificación round-robin.
Es útil comparar de un vistazo las listas enlazadas con las listas de Python:
| Operación | Lista simplemente enlazada | Array/lista de Python |
|---|---|---|
| Acceso por índice | O(n) | O(1) |
| Búsqueda por valor | O(n) | O(n) |
| Insertar al principio | O(1) | O(n) |
| Insertar al final | O(n) | O(1) amortizado |
| Insertar en medio | O(n) | O(n) |
| Eliminar al principio | O(1) | O(n) |
| Eliminar al final | O(n) | O(1) amortizado |
La idea principal: las listas enlazadas ganan en inserciones y borrados en la cabeza (O(1)), pero pierden en casi todo lo demás. Si no vas a añadir o quitar elementos con frecuencia al principio de tu estructura, probablemente te convenga más una lista de Python convencional.
Ahora que entiendes qué son las listas enlazadas, por qué las usamos y sus variantes, vamos a implementarlas en Python. El notebook de este tutorial también está disponible en este cuaderno de DataLab; si creas una copia podrás editar y ejecutar el código. ¡Es una gran opción si tienes problemas para ejecutarlo en tu equipo!
Como vimos antes, un nodo es un elemento de la lista enlazada que almacena datos y una referencia al siguiente nodo de la secuencia. Así puedes definir un nodo en Python:
class Node:
def __init__(self, data):
self.data = data
self.next = None
def __repr__(self):
return f"Node({self.data})"Este código inicializa un nodo realizando dos acciones principales: al atributo «data» del nodo se le asigna el valor que representa la información que debe contener. El atributo «next» representa la dirección del siguiente nodo. Ahora mismo está establecido en None, lo que indica que no enlaza con ningún otro nodo de la lista. A medida que añadamos nodos, este atributo se actualizará para apuntar al nodo siguiente.
A continuación, necesitamos crear la clase de la lista enlazada. Aquí encapsularemos todas las operaciones para gestionar los nodos, como inserción y eliminación. Empezaremos inicializando la lista enlazada:
class LinkedList:
def __init__(self):
self.head = None # Initialize head as NoneAl establecer self.head en None, indicamos que la lista enlazada está vacía inicialmente y no hay nodos a los que apuntar. Ahora vamos a poblarla insertando nuevos nodos.
Dentro de la clase LinkedList vamos a añadir un método para crear un nodo nuevo y colocarlo al inicio de la lista:
def insertAtBeginning(self, new_data):
new_node = Node(new_data) # Create a new node
new_node.next = self.head # Next for new node becomes the current head
self.head = new_node # Head now points to the new nodeCada vez que llames a este método se creará un nuevo nodo con los datos que indiques. El puntero next de ese nuevo nodo se establece en la cabeza actual de la lista, colocándolo delante de los nodos existentes. Por último, el nuevo nodo pasa a ser la cabeza de la lista.
Ahora vamos a poblar la lista enlazada con una serie de palabras para entender mejor cómo funciona la inserción. Para ello, primero crearemos un método para recorrer e imprimir el contenido de la lista:
def printList(self):
temp = self.head # Start from the head of the list
while temp:
print(temp.data,end=' ') # Print the data in the current node
temp = temp.next # Move to the next node
print() # Ensures the output is followed by a new lineEste método imprimirá el contenido de nuestra lista enlazada. Ahora usaremos los métodos definidos para poblarla con las palabras: «the quick brown fox».
if __name__ == '__main__':
# Create a new LinkedList instance
llist = LinkedList()
# Insert each letter at the beginning using the method we created
llist.insertAtBeginning('fox')
llist.insertAtBeginning('brown')
llist.insertAtBeginning('quick')
llist.insertAtBeginning('the')
# Now 'the' is the head of the list, followed by 'quick', then 'brown' and 'fox'
# Print the list
llist.printList()Las líneas anteriores deberían mostrar el siguiente resultado:
"the quick brown fox"
Ahora crearemos un método llamado insertAtEnd dentro de la clase LinkedList para crear un nodo nuevo al final de la lista. Si la lista está vacía, el nuevo nodo se convertirá en la cabeza. De lo contrario, se añadirá al último nodo actual. Veamos cómo funciona:
def insertAtEnd(self, new_data):
new_node = Node(new_data)
if self.head is None:
self.head = new_node
return
last = self.head
while last.next:
last = last.next
last.next = new_nodeEl método empieza creando un nodo nuevo. Después comprueba si la lista está vacía; si lo está, el nuevo nodo se asigna como cabeza. Si no, recorre la lista para encontrar el último nodo y establece su puntero hacia el nuevo nodo.
Ahora hay que incluir este método en la clase LinkedList y usarlo para añadir una palabra al final de la lista. Para ello, modifica tu función principal así:
if __name__ == '__main__':
llist = LinkedList()
# Insert words at the beginning
llist.insertAtBeginning('fox')
llist.insertAtBeginning('brown')
llist.insertAtBeginning('quick')
llist.insertAtBeginning('the')
# Insert a word at the end
llist.insertAtEnd('jumps')
# Print the list
llist.printList()Como ves, simplemente hemos llamado al método insertAtEnd para añadir la palabra «jumps» al final de la lista. El código anterior debería mostrar:
"the quick brown fox jumps"
Eliminar el primer nodo de una lista enlazada es sencillo: basta con apuntar la cabeza de la lista al segundo nodo. Así, el primero deja de formar parte de la lista. Para lograrlo, incluye este método en la clase LinkedList:
def deleteFromBeginning(self):
if self.head is None:
return "The list is empty" # If the list is empty, return this string
self.head = self.head.next # Otherwise, remove the head by making the next node the new headPara eliminar el último nodo, hay que recorrer la lista hasta encontrar el penúltimo y cambiar su puntero next a None. Así, el último nodo deja de formar parte de la lista. Copia y pega este método en tu clase LinkedList para hacerlo:
def deleteFromEnd(self):
if self.head is None:
return "The list is empty"
if self.head.next is None:
self.head = None # If there's only one node, remove the head by making it None
return
temp = self.head
while temp.next.next: # Otherwise, go to the second-last node
temp = temp.next
temp.next = None # Remove the last node by setting the next pointer of the second-last node to NoneEl método primero comprueba si la lista está vacía y, de estarlo, devuelve un mensaje. Si la lista tiene un solo nodo, lo elimina. En listas con varios nodos, localiza el penúltimo y actualiza su referencia next a None.
Actualicemos ahora la función principal para eliminar elementos del inicio y del final de la lista enlazada:
if __name__ == '__main__':
llist = LinkedList()
# Insert words at the beginning
llist.insertAtBeginning('fox')
llist.insertAtBeginning('brown')
llist.insertAtBeginning('quick')
llist.insertAtBeginning('the')
# Insert a word at the end
llist.insertAtEnd('jumps')
# Print the list before deletion
print("List before deletion:")
llist.printList()
# Deleting nodes from the beginning and end
llist.deleteFromBeginning()
llist.deleteFromEnd()
# Print the list after deletion
print("List after deletion:")
llist.printList()Este código imprimirá la lista antes y después del borrado, mostrando cómo funcionan las operaciones de inserción y eliminación en las listas enlazadas. Deberías ver esta salida:
List before deletion:
the quick brown fox jumps
List after deletion:
quick brown foxLa última operación de este capítulo es recuperar un valor concreto en la lista. Para ello, el método debe empezar en la cabeza e iterar por cada nodo comprobando si los datos del nodo coinciden con el valor de búsqueda. Aquí tienes una implementación práctica:
def search(self, value):
current = self.head # Start with the head of the list
position = 0 # Counter to keep track of the position
while current: # Traverse the list
if current.data == value: # Compare the list's data to the search value
return f"Value '{value}' found at position {position}" # Print the value if a match is found
current = current.next
position += 1
return f"Value '{value}' not found in the list" Para buscar valores concretos en la lista enlazada que hemos creado, actualiza tu función principal para incluir el método de búsqueda que acabamos de definir:
if __name__ == '__main__':
llist = LinkedList()
# Insert words at the beginning
llist.insertAtBeginning('fox')
llist.insertAtBeginning('brown')
llist.insertAtBeginning('quick')
llist.insertAtBeginning('the')
# Insert a word at the end
llist.insertAtEnd('jumps')
# Print the list before deletion
print("List before deletion:")
llist.printList()
# Deleting nodes from beginning and end
llist.deleteFromBeginning()
llist.deleteFromEnd()
# Print the list after deletion
print("List after deletion:")
llist.printList()
# Search for 'quick' and 'lazy' in the list
print(llist.search('quick')) # Expected to find
print(llist.search('lazy')) # Expected not to findEl código anterior mostrará esta salida:
List before deletion:
the quick brown fox jumps
List after deletion:
quick brown fox
Value 'quick' found at position 0
Value 'lazy' not found in the listLa palabra «quick» se ha localizado correctamente en la lista enlazada porque está en la primera posición. Sin embargo, «lazy» no forma parte de la lista y, por tanto, no se encuentra.
¡Enhorabuena si has llegado hasta aquí! Ahora tienes una base sólida sobre los principios de las listas enlazadas: su estructura, tipos, cómo añadir y eliminar elementos y cómo recorrerlas.
Pero el camino no termina aquí. Las listas enlazadas son solo la puerta de entrada al mundo de las estructuras de datos y los algoritmos. Aquí tienes algunos posibles próximos pasos para profundizar:
Explora aplicaciones prácticas de las listas enlazadas integrándolas en un proyecto de programación o de ciencia de datos. Se usan para desarrollar sistemas de archivos, construir tablas hash e incluso crear sistemas de navegación GPS y juegos de mesa. Para empezar con tus propios proyectos, echa un vistazo a nuestros proyectos de ciencia de datos guiados y gratuitos que te enseñan a resolver problemas reales en Python, R y SQL.
Aprender otras estructuras de datos, como árboles, pilas y colas, es el siguiente paso natural tras entender las listas enlazadas. Estas estructuras se basan en los mismos principios y te ayudan a resolver con eficiencia un abanico más amplio de problemas computacionales. Los árboles y los árboles binarios de búsqueda, por ejemplo, amplían el concepto de las listas enlazadas a una forma jerárquica que permite que cada nodo se conecte con múltiples elementos.
Si estos conceptos te suenan lejanos, ¡tranquilo! Datacamp tiene un curso completo de estructuras de datos y algoritmos en Python que te guiará en detalle. Empezarás con estructuras como pilas, árboles, tablas hash, colas y grafos. A medida que avances, comprenderás algoritmos de búsqueda y ordenación, lo que te ayudará a ser un programador y un resolutor de problemas más eficaz.
En este tutorial hemos implementado listas simplemente enlazadas, cubriendo operaciones como inserción, eliminación y recorrido.
Puedes ir un paso más allá aprendiendo a implementar listas doblemente enlazadas y circulares. Las skip lists son otra extensión de las listas enlazadas que permite búsquedas más rápidas facilitando el acceso acelerado a elementos.
Aprender estas estructuras avanzadas llevará tus habilidades técnicas al siguiente nivel y mejorará notablemente tu capacidad de programación, preparándote para retos más complejos en ciencia de datos, desarrollo de software e ingeniería de machine learning.
Si prefieres una introducción a la programación más amigable antes de abordar estos temas avanzados, explora el itinerario Python Programmer. Ofrece una serie de cursos para aprender los fundamentos del lenguaje.
¡Sigue aprendiendo Python!
programa
programa
Curso
Tutorial
Adel Nehme
Tutorial
Abid Ali Awan
Tutorial
Sejal Jaiswal
Tutorial
DataCamp Team
Tutorial
DataCamp Team
Tutorial
Sejal Jaiswal
