
Programma
Sviluppare modelli linguistici di grandi dimensioni
16 h
Non ti senti a tuo agio a inviare i tuoi prompt a un server cloud? La sicurezza è una grande preoccupazione per molti, e a ragione.
Scegli ChatGPT o Claude, scrivi un prompt e la richiesta finisce nell'infrastruttura di qualcun altro. Per la maggior parte dei casi d'uso va bene. Ma se lavori con dati sensibili o codice proprietario, potrebbe essere un rischio per la sicurezza. Inoltre, le interfacce cloud ti vincolano a modelli specifici, limiti di velocità e piani tariffari.
Open WebUI è un'interfaccia browser self-hosted per interagire con LLM. È proprio come l'interfaccia di ChatGPT, ma gira sulla tua macchina. Si connette a Ollama, API compatibili con OpenAI e modelli locali, così i tuoi dati restano dove li metti tu.
In questo articolo ti guiderò nell'installazione di Open WebUI con Docker, nel collegamento a un modello locale e nel suo utilizzo per attività reali come chat e generazione di codice.
Open WebUI è un'interfaccia di chat basata su browser per interagire con LLM - simile a ChatGPT, ma in esecuzione sulla tua macchina.
L'architettura è ridotta all'osso. C'è un frontend a cui accedi dal browser e un backend che si collega a provider di modelli come Ollama o qualsiasi API compatibile con OpenAI.
Quindi, Open WebUI non esegue i modelli: parla semplicemente con qualunque backend tu gli indichi.
Pensalo come una porta d'ingresso universale per il tuo setup di IA locale.
Questo significa che puoi sostituire il backend del modello senza toccare l'interfaccia, e puoi far girare l'interfaccia su una macchina mentre il modello gira su un'altra.
Con Open WebUI ottieni:
Se hai usato ChatGPT o Claude, l'interfaccia ti sarà familiare. La differenza sta in ciò che gira dietro. Vediamolo subito.
Docker è il modo più rapido per far partire Open WebUI, e lo esegue anche in completa isolazione.
Ti serve Docker installato sulla tua macchina. Se non ce l'hai ancora, scaricalo dal sito ufficiale di Docker.
Ollama è opzionale in questa fase. Se vuoi collegare subito Open WebUI a un modello locale, installa prima Ollama e scarica almeno un modello. Se vuoi solo far partire l'interfaccia e collegarla dopo, salta questo passaggio per ora.
Esegui questo comando per scaricare l'immagine di Open WebUI e avviare il container:
docker run -d \
-p 3000:8080 \
-v open-webui:/app/backend/data \
--name open-webui \
--restart always \
ghcr.io/open-webui/open-webui:main
Download dell'immagine Open WebUI
Ecco cosa fa ciascun flag:
d esegue il container in background
p 3000:8080 mappa la porta 8080 all'interno del container sulla porta 3000 della tua macchina
v open-webui:/app/backend/data crea un volume Docker per mantenere i tuoi dati: conversazioni, impostazioni e file caricati restano dopo i riavvii del container
-restart always riavvia il container se si ferma o se la macchina si riavvia
-name open-webui assegna al container un nome leggibile per poterlo richiamare in seguito
Una volta avviato il container, apri il browser e vai su http://localhost:3000.
Al primo accesso, Open WebUI ti chiederà di creare un account admin. Inserisci nome, email e password.
Pagina di configurazione di Open WebUI
Dopodiché sei dentro. L'interfaccia si carica e sei pronto a collegare un modello.
Home page di Open WebUI
Ollama è il backend più comune per Open WebUI perché rende l'esecuzione dei modelli locali estremamente semplice: un comando per scaricare un modello, un altro per eseguirlo.
Prima di collegare qualsiasi cosa, assicurati che Ollama sia effettivamente in esecuzione. Apri un terminale e verifica:
ollama serve
Verifica che Ollama sia in esecuzione
Se Ollama è già attivo come servizio in background, vedrai un messaggio che indica che l'indirizzo è già in uso. Va bene: significa che è avviato.
Poi verifica di aver scaricato almeno un modello. Esegui:
ollama list
Modelli Ollama disponibili
Se l'elenco è vuoto, scarica prima un modello. Mistral è un buon punto di partenza:
ollama pull mistral
Download del modello Mistral
Mistral è un solido modello generico che gira bene su hardware consumer.
Ora apri Open WebUI nel browser all'indirizzo http://localhost:3000. Vai su Settings - Connections e controlla l'URL dell'API di Ollama. Per impostazione predefinita è http://host.docker.internal:11434.
Impostazione dell'URL API di Ollama
Questo funziona su Mac e Windows con Docker Desktop. Su Linux, sostituisci host.docker.internal con l'IP effettivo dell'host:
http://<your-ip-address>:11434Clicca su Save e aggiorna la pagina. Se la connessione è riuscita, i tuoi modelli Ollama appariranno nel selettore dei modelli in cima alla finestra di chat. Selezionane uno e sei pronto per iniziare a chattare.
Modelli disponibili
Se non compaiono modelli, ricontrolla che Ollama sia in esecuzione e che l'URL dell'API sia corretto per il tuo sistema operativo.
Una volta collegato il modello, usare Open WebUI è molto simile a ChatGPT, ma con qualche controllo extra che vale la pena conoscere.
In cima alla finestra di chat vedrai un menu a discesa per la selezione del modello. Cliccaci e scegli il modello che vuoi usare. Se hai collegato più backend, qui compaiono tutti i modelli disponibili: modelli Ollama, modelli via API, tutto in un unico elenco.
Scrivi il tuo prompt nel campo in basso e premi Invio. Le risposte arrivano in streaming in tempo reale, quindi non devi attendere la fine dell'output per iniziare a leggere.
Esempio di chat di base
Ogni conversazione viene salvata nella barra laterale sinistra. Puoi rinominare le conversazioni per tenere tutto in ordine o eliminare quelle che non ti servono. Clicca su qualsiasi conversazione passata per riprendere da dove eri rimasto.
Open WebUI funziona bene per generazione e debug del codice. Descrivi in linguaggio naturale ciò di cui hai bisogno e il modello restituirà un blocco di codice da copiare.
Esempio di coding
Per il debug, incolla nel prompt il tuo codice e il messaggio di errore. Sii specifico: includi l'output di errore completo, non solo il tipo di errore. Più contesto dai, più utile sarà la risposta.
Esempio di debug
Per attività in più passaggi, non cercare di far entrare tutto in un unico prompt. Spezzale. Chiedi al modello di scrivere una funzione, poi di aggiungere la gestione degli errori, poi di scrivere i test. Prompt più brevi e mirati danno risultati migliori di quelli lunghi che cercano di fare tutto insieme.
Open WebUI supporta il caricamento di file in chat. Clicca sull'icona con il segno più nell'area di input e allega un documento: PDF, file di testo o simili.
Una volta caricato, il contenuto del file entra a far parte del contesto della conversazione. Puoi chiedere al modello di riassumerlo, estrarre informazioni specifiche o rispondere a domande basate su ciò che c'è nel documento.
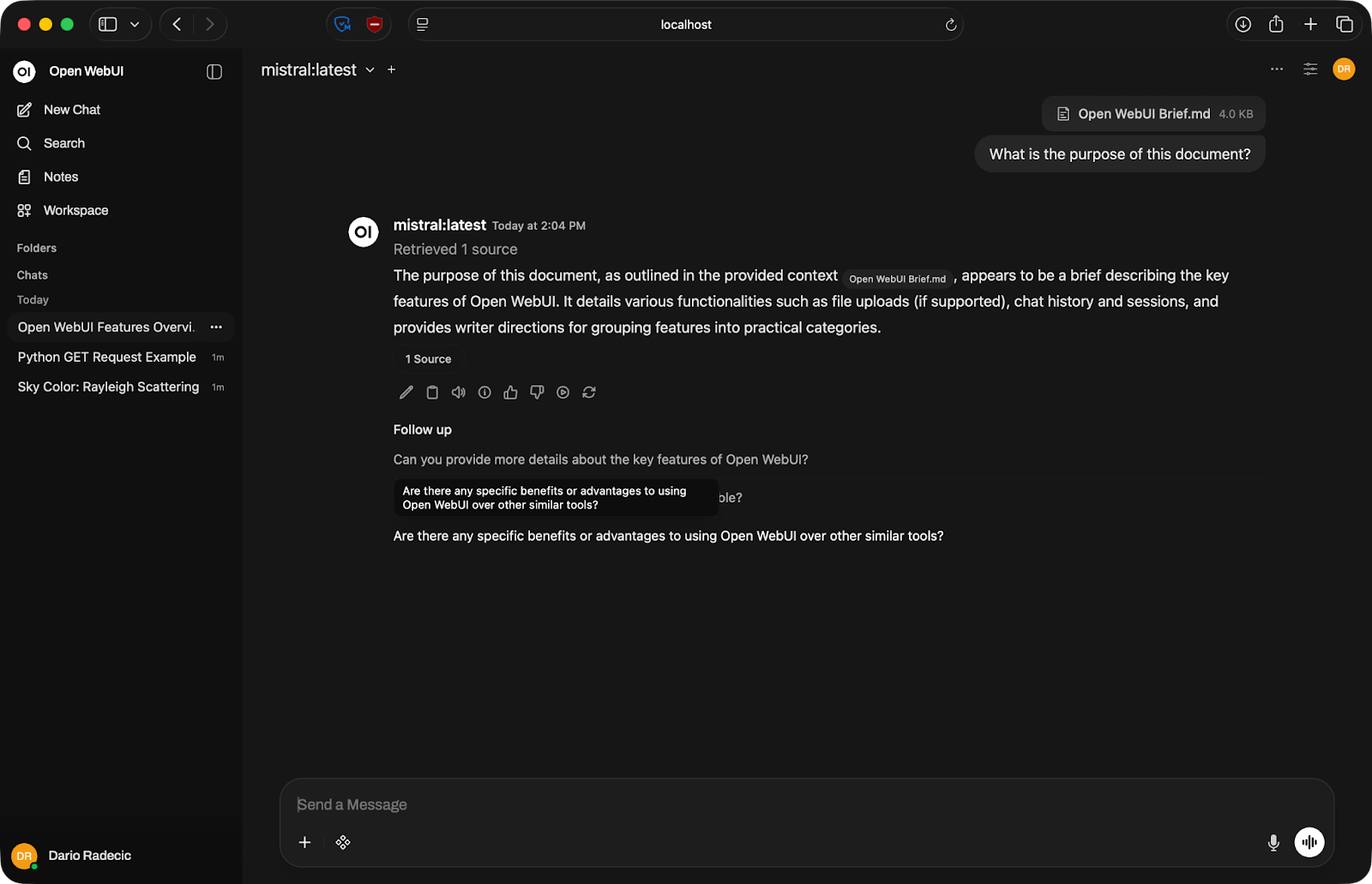
Conversazione su documento
Tieni presente che il modello può lavorare solo con ciò che rientra nella sua finestra di contesto, ovvero la quantità massima di testo che può elaborare in una volta. I file molto grandi potrebbero essere tagliati, quindi dividili se stai lavorando con documenti lunghi.
Open WebUI ha molte impostazioni, quindi passo in rassegna quelle che ti interesseranno davvero.
Il selettore del modello in cima alla finestra di chat ti permette di cambiare modello a sessione in corso senza avviare una nuova conversazione. Torna utile quando vuoi testare lo stesso prompt su modelli diversi: eseguilo con Llama, poi con Mistral e confronta i risultati affiancati.
Selezione del modello
Se stai valutando modelli per un'attività specifica, questo fa risparmiare molto tempo.
Ogni conversazione viene salvata e mostrata nella barra laterale sinistra. Puoi rinominare le sessioni con qualcosa di significativo, così da non ritrovarti poi con un elenco di "Nuova chat".

Sessioni di chat precedenti
Questo rende Open WebUI utile per lavori continuativi. Puoi tornare a una sessione di coding, continuare un prompt a metà o riutilizzare una conversazione come riferimento.
A Open WebUI non importa cosa gira dietro. Puoi collegare un modello locale di Ollama per lavori privati e un'API compatibile con OpenAI per attività in cui hai un modello closed-source che comunque non entrerebbe in memoria.
Gestione delle connessioni OpenAI
Usa un modello locale piccolo per compiti rapidi e un modello più grande via API quando il lavoro lo richiede (e lo consente).
Puoi personalizzare moltissimo i singoli LLM.
Nelle impostazioni del modello puoi regolare il prompt di sistema, aggiungere una base di conoscenza (documenti) e collegare il modello a tool e skill. Puoi anche modificare per quali capacità verrà usato il modello, come visione, caricamento file, e scegliere se il modello deve svolgere attività come la ricerca sul web:
Regolazione delle impostazioni del modello
Open WebUI non vuole sostituire ChatGPT. Serve piuttosto a risolvere un problema diverso.
La differenza fondamentale è dove vanno i tuoi dati. Con ChatGPT, ogni prompt va ai server di OpenAI. Con Open WebUI, tutto resta sulla tua macchina: interfaccia, modello e cronologia delle conversazioni.
Il compromesso è la performance. GPT-5 e modelli cloud simili sono più capaci della maggior parte dei modelli che puoi eseguire in locale. Se la priorità è la qualità pura dell'output, vince il cloud. Se contano di più privacy o accesso offline, vince il locale.
Anche il costo è un fattore. ChatGPT Plus ha un canone mensile fisso. Open WebUI è gratuito, ma paghi con l'hardware: una macchina con abbastanza RAM e, idealmente, una GPU.
La CLI di Ollama va bene per test rapidi, ma non è pensata per il lavoro reale. Scrivi un prompt, ottieni una risposta e finisce lì. Niente cronologia, niente caricamenti di file e nessun modo di confrontare modelli senza cambiare terminale.
Open WebUI dà a Ollama un'interfaccia vera. Modelli e backend sono gli stessi, ma con gestione delle conversazioni, controlli delle impostazioni e una UI che non scompare quando chiudi il terminale.
Se già usi Ollama, aggiungere Open WebUI sopra non costa nulla e migliora di molto l'esperienza d'uso.
LM Studio è un'app desktop con un browser dei modelli integrato e un'interfaccia di chat simile. È una buona opzione se vuoi una GUI autonoma senza Docker. Lo svantaggio è che è legata al tuo desktop: Open WebUI gira nel browser e può essere accessibile da altri dispositivi sulla tua rete.
text-generation-webui è più uno strumento per power user. Supporta una gamma più ampia di formati di modelli e offre controlli più granulati, ma il setup è più impegnativo e l'interfaccia è più difficile da navigare. Open WebUI è il punto di partenza migliore a meno che tu non abbia bisogno specifico di ciò che offre text-generation-webui.
Puoi fare riferimento a questa tabella per un rapido confronto tra Open WebUI e le sue alternative:
Open WebUI rispetto alle alternative
La maggior parte dei problemi con Open WebUI rientra in cinque categorie, e spesso c'è una soluzione rapida.
Esegui docker logs open-webui subito dopo l'avvio fallito. I log ti diranno cos'è andato storto. Nove volte su dieci è un conflitto di porta o un problema di permessi sul volume.
Se la porta 3000 è già in uso sulla tua macchina, il container non partirà. Risolvi mappando a una porta host diversa:
docker run -d -p 3001:8080 ...Poi accedi a Open WebUI su http://localhost:3001.
Per prima cosa, conferma che Ollama sia effettivamente in esecuzione:
ollama servePoi controlla l'URL dell'API in Settings - Connections. Su Mac e Windows dovrebbe essere http://host.docker.internal:11434. Su Linux usa l'indirizzo IP della tua macchina host. Un URL errato qui è la causa più comune dei fallimenti di connessione.
Se il selettore dei modelli è vuoto, Open WebUI si è collegato a Ollama ma non ha trovato modelli. Esegui ollama list per confermare di aver scaricato almeno un modello. Se l'elenco è vuoto, scaricane uno:
ollama pull mistralDopo il download, aggiorna la pagina di Open WebUI: non si aggiorna automaticamente.
Le risposte lente sono quasi sempre un problema di hardware, non di Open WebUI. Il modello è troppo grande per la RAM disponibile o non hai una GPU. Passa a un modello più piccolo: i modelli da 7B parametri girano discretamente sulla maggior parte delle macchine moderne con 16 GB di RAM. Se usi solo la CPU, aspettati risposte più lente a prescindere dalla dimensione del modello.
Alcune abitudini faranno una grande differenza nell'uso quotidiano di Open WebUI.
Open WebUI è adatto a situazioni specifiche, non a tutte. Ecco quando usarlo:
Detto ciò, Open WebUI non è lo strumento giusto se ti serve la massima qualità di output e la privacy non è un problema. In quel caso è meglio un'API cloud.
Open WebUI ti offre un'interfaccia pulita e pratica per lavorare con modelli locali, e hai il pieno controllo dell'ambiente.
Nessun dato lascia la tua macchina, nessun rate limit, nessun abbonamento richiesto. Scegli i modelli, gestisci le impostazioni e ampli il setup come preferisci.
Il modo migliore per iniziare è mantenerlo semplice. Avvia il container Docker, collega un modello piccolo come Llama o Mistral e invia qualche prompt. Una volta che funziona, puoi aggiungere altri modelli, configurare i prompt di sistema, collegare API esterne e costruire da lì.
Nel caso te lo stessi chiedendo, puoi anche eseguire Ollama con Docker senza alcuna configurazione locale. Leggi la nostra guida recente per scoprire come.
Impara con Datazcamp
Programma
Corso
Corso
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min

