
Cursus
Développer des LLM
16 h
Hésitez-vous à envoyer vos invites vers un serveur cloud ? La sécurité est une préoccupation majeure, et à juste titre.
Vous choisissez ChatGPT ou Claude, vous saisissez une invite, et la requête part vers l'infrastructure de quelqu'un d'autre. Dans la plupart des cas, cela convient. Mais si vous travaillez avec des données sensibles ou du code propriétaire, le risque existe. De plus, les interfaces cloud vous enferment dans des modèles spécifiques, des limites de taux et des forfaits tarifaires.
Open WebUI est une interface auto-hébergée, accessible depuis le navigateur, pour interagir avec des LLM. C'est l'interface de ChatGPT, mais qui tourne sur votre propre machine. Elle se connecte à Ollama, à des API compatibles OpenAI et à des modèles locaux, afin que vos données restent chez vous.
Dans cet article, je vous guide pas à pas pour installer Open WebUI avec Docker, le connecter à un modèle local et l'utiliser pour des cas concrets comme la conversation et la génération de code.
Open WebUI est une interface de chat dans le navigateur pour interagir avec des LLM — similaire à ChatGPT, mais exécutée sur votre propre machine.
L'architecture est on ne peut plus simple : une interface front-end à laquelle vous accédez dans votre navigateur, et un back-end qui se connecte à des fournisseurs de modèles comme Ollama ou toute API compatible OpenAI.
Autrement dit, Open WebUI n'exécute pas les modèles : il discute simplement avec le back-end que vous lui indiquez.
Voyez-le comme la porte d'entrée universelle de votre environnement IA local.
Vous pouvez donc changer de back-end de modèle sans toucher à l'interface, et faire tourner l'interface sur une machine tandis que le modèle tourne sur une autre.
Avec Open WebUI, vous bénéficiez de :
Si vous avez utilisé ChatGPT ou Claude, l'interface vous semblera familière. La différence se joue en coulisses. Voyons cela de plus près.
Docker est la façon la plus rapide de faire tourner Open WebUI, tout en l'isolant complètement.
Vous devez avoir Docker installé sur votre machine. Si ce n'est pas le cas, récupérez-le sur le site officiel de Docker.
Ollama est facultatif à ce stade. Si vous souhaitez connecter immédiatement Open WebUI à un modèle local, installez d'abord Ollama et téléchargez au moins un modèle. Si vous voulez simplement lancer l'interface et la connecter plus tard, passez cette étape pour l'instant.
Exécutez cette commande pour récupérer l'image Open WebUI et démarrer le conteneur :
docker run -d \
-p 3000:8080 \
-v open-webui:/app/backend/data \
--name open-webui \
--restart always \
ghcr.io/open-webui/open-webui:main
Téléchargement de l'image Open WebUI
Voici à quoi servent les indicateurs :
d exécute le conteneur en arrière-plan
p 3000:8080 fait correspondre le port 8080 à l'intérieur du conteneur au port 3000 sur votre machine
v open-webui:/app/backend/data crée un volume Docker pour pérenniser vos données : conversations, paramètres et fichiers téléversés subsistent après les redémarrages du conteneur
-restart always relance le conteneur s'il s'arrête ou si votre machine redémarre
-name open-webui attribue un nom explicite au conteneur pour le référencer ensuite
Une fois le conteneur démarré, ouvrez votre navigateur et rendez-vous sur http://localhost:3000.
Au premier accès, Open WebUI vous demandera de créer un compte administrateur. Renseignez votre nom, votre e-mail et un mot de passe.
Page de configuration d'Open WebUI
Après cela, vous y êtes. L'interface se charge et vous pouvez connecter un modèle.
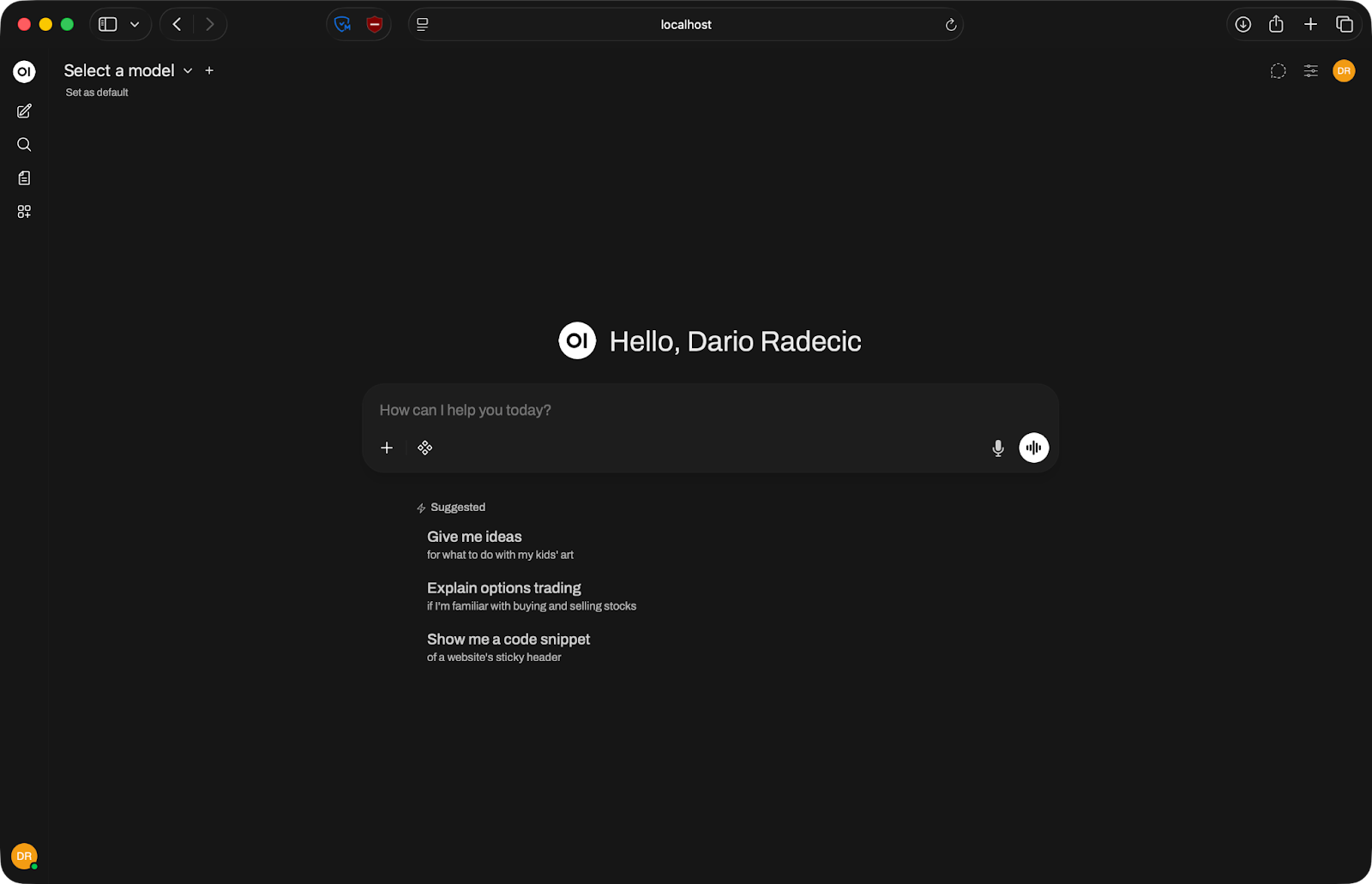
Page d'accueil d'Open WebUI
Ollama est le back-end le plus courant pour Open WebUI car il rend l'exécution de modèles locaux ultra simple : une commande pour télécharger un modèle, une autre pour le lancer.
Avant toute connexion, assurez-vous qu'Ollama tourne bien. Ouvrez un terminal et vérifiez :
ollama serve
Vérification du fonctionnement d'Ollama
Si Ollama s'exécute déjà en arrière-plan, un message indiquera que l'adresse est déjà utilisée. C'est bon signe : cela signifie qu'il est actif.
Ensuite, vérifiez que vous avez au moins un modèle téléchargé. Lancez :
ollama list
Modèles Ollama disponibles
Si la liste est vide, téléchargez d'abord un modèle. Mistral est un excellent point de départ :
ollama pull mistral
Téléchargement du modèle Mistral
Mistral est un très bon modèle généraliste qui s'exécute bien sur du matériel grand public.
Ouvrez maintenant Open WebUI dans votre navigateur à l'adresse http://localhost:3000. Allez dans Settings - Connections et vérifiez l'URL de l'API Ollama. Par défaut, elle est définie sur http://host.docker.internal:11434.
Configuration de l'URL de l'API Ollama
Cette configuration fonctionne sur Mac et Windows avec Docker Desktop. Sous Linux, remplacez host.docker.internal par l'adresse IP de votre hôte :
http://<your-ip-address>:11434Cliquez sur Save puis actualisez la page. Si la connexion réussit, vos modèles Ollama apparaîtront dans le sélecteur de modèles en haut de la fenêtre de chat. Sélectionnez-en un et vous pouvez commencer à discuter.
Modèles disponibles
Si aucun modèle n'apparaît, vérifiez qu'Ollama tourne et que l'URL de l'API est correcte pour votre système.
Une fois votre modèle connecté, Open WebUI s'utilise comme ChatGPT — avec quelques contrôles supplémentaires utiles à connaître.
En haut de la fenêtre, vous trouverez un menu déroulant pour sélectionner le modèle. Cliquez et choisissez celui que vous voulez utiliser. Si vous avez connecté plusieurs back-ends, tous les modèles disponibles s'affichent ici : modèles Ollama, modèles via API, tout au même endroit.
Saisissez votre invite dans le champ en bas puis appuyez sur Entrée. Les réponses s'affichent en flux continu : vous pouvez lire sans attendre la fin générale de la sortie.
Exemple de chat de base
Chaque conversation est enregistrée dans la barre latérale gauche. Vous pouvez renommer les conversations pour rester organisé, ou supprimer celles devenues inutiles. Cliquez sur une conversation passée pour reprendre là où vous vous étiez arrêté.
Open WebUI fonctionne très bien pour générer et déboguer du code. Décrivez clairement votre besoin en langage naturel : le modèle renverra un bloc de code à copier.
Exemple de génération de code
Pour le débogage, collez votre code et le message d'erreur dans l'invite. Soyez précis : incluez l'intégralité de la sortie d'erreur, pas seulement le type. Plus vous fournissez de contexte, meilleure sera la réponse.
Exemple de débogage
Pour les tâches en plusieurs étapes, évitez de tout faire tenir dans une seule invite. Découpez-les : demandez au modèle d'écrire une fonction, puis d'y ajouter la gestion d'erreurs, puis d'écrire des tests. Des invites courtes et ciblées donnent de meilleurs résultats que des pavés qui tentent de tout faire d'un coup.
Open WebUI prend en charge le téléversement de fichiers dans le chat. Cliquez sur l'icône plus dans la zone de saisie et joignez un document : PDF, fichier texte, etc.
Une fois téléversé, le contenu du fichier est ajouté au contexte de la conversation. Vous pouvez demander au modèle de le résumer, d'en extraire des informations précises ou de répondre à des questions basées sur ce document.
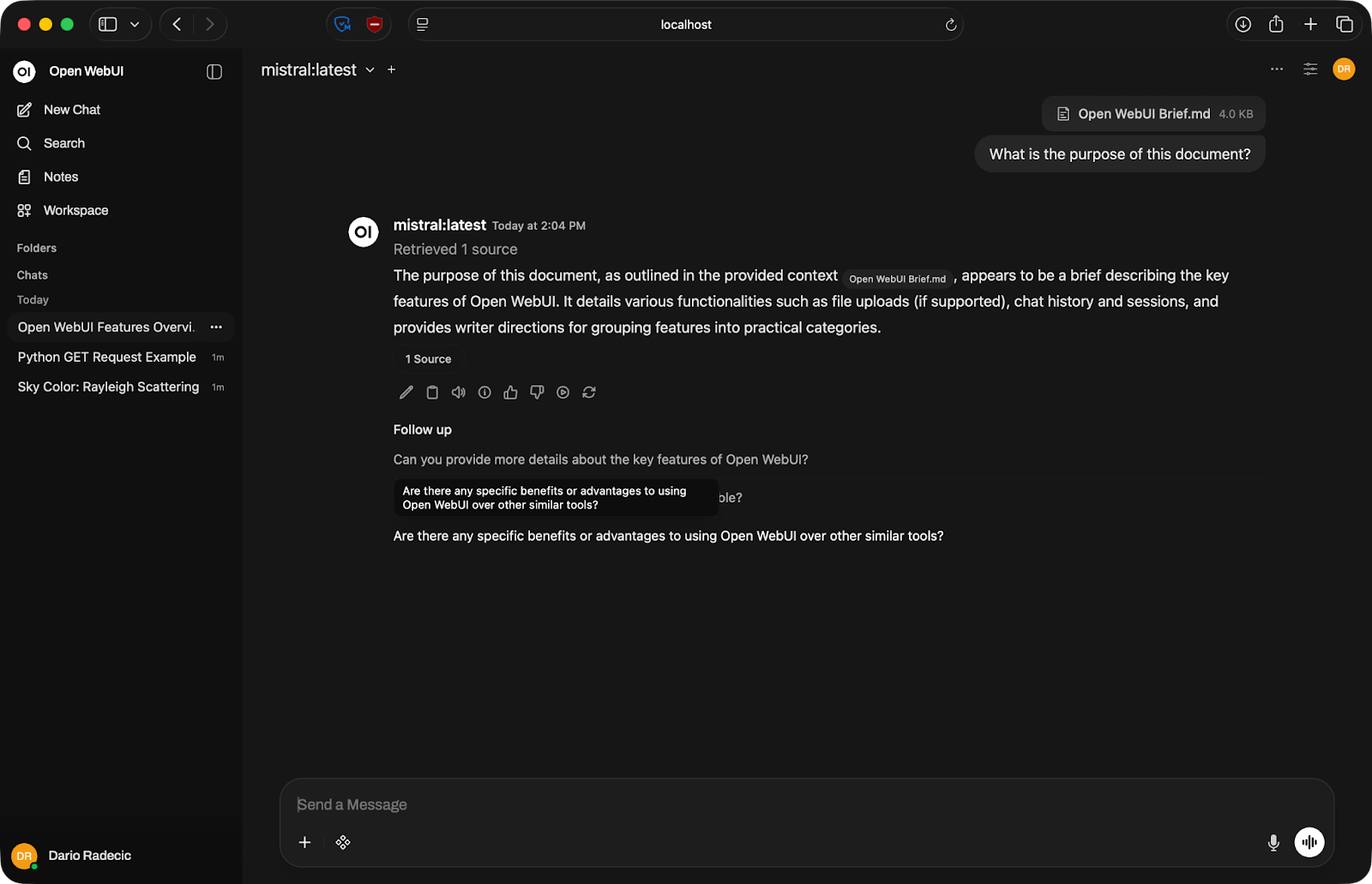
Conversation autour d'un document
Gardez à l'esprit que le modèle ne peut travailler que dans la limite de sa fenêtre de contexte — la quantité maximale de texte qu'il peut traiter d'un coup. Les très gros fichiers peuvent être tronqués : scindez-les si vous travaillez sur des documents longs.
Open WebUI propose de nombreux réglages ; voici ceux qui vous seront vraiment utiles.
Le sélecteur de modèle en haut de la fenêtre vous permet de changer de modèle en cours de session sans repartir de zéro. Idéal pour tester la même invite sur différents modèles : lancez-la avec Llama, puis Mistral, et comparez les sorties côte à côte.
Sélection du modèle
Si vous évaluez des modèles pour une tâche donnée, vous gagnez beaucoup de temps.
Chaque conversation est enregistrée et listée dans la barre latérale gauche. Vous pouvez renommer les sessions de façon explicite pour éviter une liste de « New Chat » incompréhensibles.

Sessions de chat précédentes
Cela rend Open WebUI pertinent pour un travail suivi : revenir sur une session de code, poursuivre une invite inachevée ou réutiliser une conversation comme référence.
Open WebUI est agnostique sur ce qui tourne derrière. Vous pouvez connecter un modèle local via Ollama pour les travaux privés et une API compatible OpenAI pour les tâches où un modèle propriétaire, de toute façon trop volumineux pour votre mémoire, est nécessaire.
Gestion des connexions OpenAI
Utilisez un petit modèle local pour les tâches rapides et un modèle plus grand via API lorsque c'est nécessaire (et autorisé).
Vous pouvez personnaliser de nombreux aspects pour chaque LLM.
Dans les paramètres du modèle, vous pouvez ajuster l'invite système, ajouter une base de connaissances (documents) et connecter le modèle à des outils et des compétences. Vous pouvez également définir les capacités utilisées par le modèle, comme la vision, le téléversement de fichiers, ou s'il doit effectuer des recherches web :
Ajustement des paramètres du modèle
Open WebUI n'essaie pas de remplacer ChatGPT. Il répond à un besoin différent.
La différence majeure, c'est le destinataire de vos données. Avec ChatGPT, chaque invite part vers les serveurs d'OpenAI. Avec Open WebUI, tout reste sur votre machine : l'interface, le modèle et l'historique des conversations.
Le compromis porte sur les performances. GPT-5 et autres modèles cloud sont plus performants que la plupart des modèles exécutables en local. Si votre priorité est la qualité brute des résultats, le cloud s'impose. Si la confidentialité ou l'accès hors ligne priment, le local gagne.
Le coût compte aussi. ChatGPT Plus est un abonnement mensuel fixe. Open WebUI est gratuit, mais vous payez avec le matériel : une machine avec suffisamment de RAM et, idéalement, un GPU.
La CLI d'Ollama convient pour des tests rapides, mais n'est pas conçue pour un travail soutenu. Vous tapez une invite, recevez une réponse, et c'est tout. Pas d'historique, pas de téléversement de fichiers, pas de comparaison aisée de modèles sans changer de terminal.
Open WebUI offre à Ollama une interface digne de ce nom. Les modèles et le back-end sont les mêmes, mais avec la gestion des conversations, des réglages et une UI qui ne disparaît pas quand vous fermez le terminal.
Si vous utilisez déjà Ollama, ajouter Open WebUI par-dessus ne coûte rien et améliore nettement l'expérience utilisateur.
LM Studio est une application de bureau avec un navigateur de modèles intégré et une interface de chat similaire. Bon choix si vous voulez une application graphique autonome sans Docker. L'inconvénient : elle est liée à votre poste. Open WebUI s'exécute dans un navigateur et est accessible depuis d'autres appareils de votre réseau.
text-generation-webui s'adresse davantage aux utilisateurs avancés. Il prend en charge un plus large éventail de formats de modèles et offre des réglages plus fins, mais l'installation est plus exigeante et l'interface moins intuitive. Open WebUI est un meilleur point de départ, sauf besoin spécifique de text-generation-webui.
Référez-vous à ce tableau pour une comparaison rapide entre Open WebUI et ses alternatives :
Open WebUI face aux alternatives
La plupart des problèmes avec Open WebUI relèvent de cinq catégories — et se résolvent généralement rapidement.
Exécutez docker logs open-webui juste après l'échec de démarrage. Les journaux vous indiqueront la cause. Neuf fois sur dix, il s'agit d'un conflit de port ou d'un problème de droits sur le volume.
Si le port 3000 est déjà utilisé sur votre machine, le conteneur ne démarrera pas. Corrigez en faisant correspondre un autre port hôte :
docker run -d -p 3001:8080 ...Accédez ensuite à Open WebUI sur http://localhost:3001.
Commencez par confirmer qu'Ollama tourne bien :
ollama servePuis vérifiez l'URL de l'API dans Settings - Connections. Sur Mac et Windows, elle doit être http://host.docker.internal:11434. Sous Linux, utilisez l'adresse IP de votre machine hôte. Une URL erronée est la cause la plus fréquente d'échec de connexion.
Si le sélecteur de modèle est vide, Open WebUI s'est connecté à Ollama mais n'a trouvé aucun modèle. Lancez ollama list pour confirmer qu'au moins un modèle est téléchargé. Si la liste est vide, téléchargez-en un :
ollama pull mistralActualisez la page d'Open WebUI après le téléchargement : la liste ne se met pas à jour automatiquement.
Les réponses lentes proviennent presque toujours du matériel, pas d'Open WebUI. Le modèle est trop gros pour votre RAM disponible ou vous n'avez pas de GPU. Passez à un modèle plus petit : les modèles 7B fonctionnent raisonnablement bien sur la plupart des machines modernes avec 16 Go de RAM. En configuration 100 % CPU, attendez-vous à des réponses plus lentes, quelle que soit la taille du modèle.
Quelques habitudes améliorent nettement l'expérience au quotidien.
Open WebUI convient très bien à certains contextes — pas à tous. Voici quand l'utiliser :
Cela dit, Open WebUI n'est pas l'outil adéquat si vous recherchez la meilleure qualité de sortie et que la confidentialité n'est pas un sujet. Une API cloud sera plus appropriée.
Open WebUI vous offre une interface claire et pratique pour travailler avec des modèles locaux, tout en gardant la maîtrise totale de l'environnement.
Aucune donnée ne quitte votre machine, pas de limites de taux, pas d'abonnement. Vous choisissez les modèles, vous gérez les paramètres et vous faites évoluer la configuration selon vos besoins.
Le meilleur moyen de commencer est de rester simple : lancez le conteneur Docker, connectez un petit modèle comme Llama ou Mistral, et testez quelques invites. Une fois cela en place, ajoutez d'autres modèles, paramétrez des invites système, connectez des API externes et bâtissez la suite.
Au passage, vous pouvez aussi exécuter Ollama avec Docker sans aucune installation locale. Consultez notre guide récent pour savoir comment faire.
Learn with Datazcamp
Cursus
Cours
Cours
blog
Kurtis Pykes
9 min
blog
Vinod Chugani
14 min
blog
Kurtis Pykes
15 min
blog
Zoumana Keita
15 min
Tutoriel
Tutoriel
Adel Nehme
